Everything you need to know about threading with python

From Module 1: Parallel computing (using threads, MPI, GPU computing)
1. Threads Basics
A process can be viewed as a running program usually in an isolated environment (with its own memory) and managed by the operating system. With the evolution of processes and operating systems schedulers, it is possible to run several processes in parallel on a single machine or in a distributed environment on multiple computers: that is called multiprocessing and we will discuss more it in the next chapter.
A thread is nothing more than a running subprogram. A process can launch many threads that run in parallel (That is called multithreading). As threads belong to a single processor, they can share memory. In contrast to processes, threads are managed (created, killed, …) completely by the program that created them. Those specificities give threads multiples advantages:
- As they share a memory, they can therefore communicate and exchange information with each other easily
- We can add the fact that they do not require a lot of computer resources as processes
illustration:
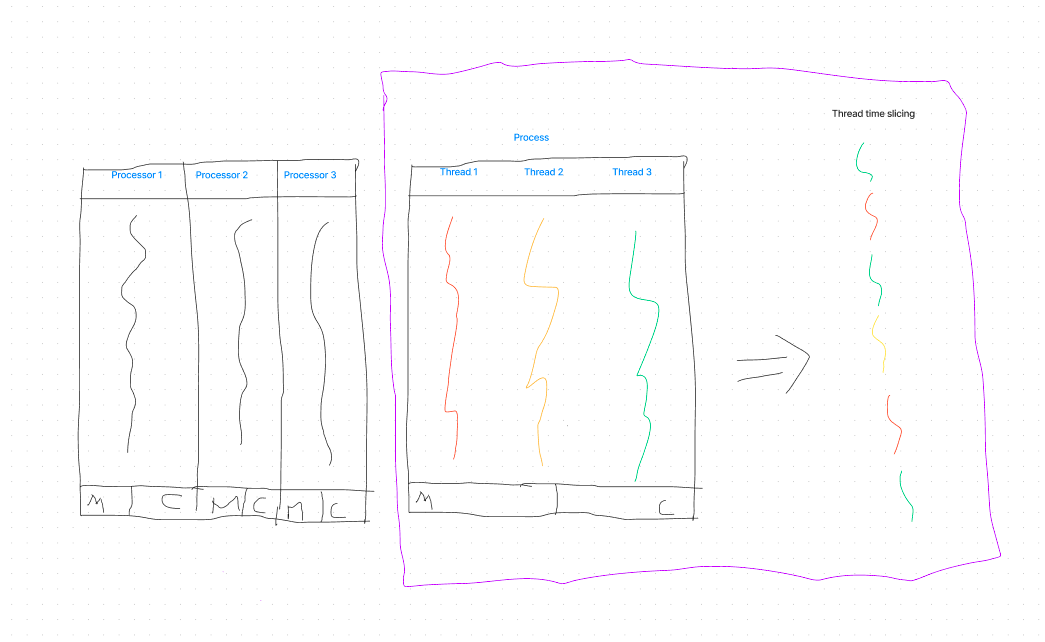
Hyper-threading is a process by which a CPU divides up its physical cores into virtual cores that are treated as if they are actually physical cores by the operating system.
2. Starting and Interrupting Threads
A thread has a starting phase, an execution sequence and a conclusion. it can be interrupted or stopped for a certain amount of time. Each thread that we create can have its own role and execution process on the computer. So it is a really good way to use the resources of a machine that we have. It may be to train a simple model with limited data or to execute whatever we want
Each programming language has its own way to deal with threads. Although The java approach is not very far from the python one, they differ in some ways. And for this reason, this section will become more technical. We will therefore choose python for the continuation and in the whole book. But I have to stress that python is very bad at multithreading because of the Global Interpreter Lock (GIL) that makes threads run almost sequentially. You may want to read more about it here
Some basic operations applicable to a thread are:
- Create
In python to create a thread, we can use the _thread module. There is a method called start_new_thread that is used for this purpose. His definition is _thread.start_new_thread ( function, args[, kwargs] ), Where function is the function we want our thread to execute and the rest of the parameters are the arguments we want to pass to our function. This module is more low-level and a more complicated way to deal with threads
- Create with threading module:
This is a more modern way to create a thread and it is really simple. It provides some useful methods to manage threads like:
- run(): The run() method is the entry point for a thread.
- start(): The start() method starts a thread by calling the run method.
- join([time]): The join() method waits for threads to terminate.
- isAlive(): It checks whether a thread is still executing.
- getName(): This returns the name of a thread.
- setName(): This method sets the name of a thread.
In order to launch a thread using the threading method, we must:
- Define a subclass of the Thread class
- Override the __init__(self [,args]) method to add additional arguments if necessary.
- Then, override the run(self[, args]) method to implement what the thread should do when started
For example:
#!/usr/bin/python
import threading
import time
class myThread (threading.Thread):
def __init__(self, message):
threading.Thread.__init__(self)
self.message = message
def run(self):
while(True):
print(self.message)
time.sleep(1)
# Create new threads
thread1 = myThread("Thread-1")
thread2 = myThread("Thread-2")
thread3 = myThread("Thread-3")
thread4 = myThread("Thread-4")
# Start new Threads
thread1.start()
thread2.start()
thread3.start()
thread4.start()The execution of this program gives this output:
Thread-1
Thread-3
Thread-4
Thread-2
Thread-1
Thread-3
Thread-4
Thread-2
Thread-1
Thread-4
Thread-3
Thread-2
Thread-1
Thread-4
Thread-3
We can see that the order of execution of those threads is not respected. And that is because of the operating system task scheduler. (see thread execution graph)
After creating a thread, we can kill it. Yeah, it is. Killing a thread is actually stopping his execution as a subprogram. This is done in different ways :
- Normally when the task, is assigned to a threaded end, it is terminated automatically
- A flag can be used to stop internally the execution of the thread
- When we raise an exception using PyThreadState_SetAsyncExc [6]
- …
3. Synchronization I: Monitors
As we saw in the last example, when different threads are started, they run in parallel in no predefined other or synchronization. It may lead to many problems like many threads trying to access the same piece of data which can lead to problems like making data inconsistent or getting garbled output (like having Hlleo instead of Hello on your console). Such problems can arise when we don’t tell the computer how to Manage threads in an organized manner. The synchronization concept is very important in threads. There are many cases where we need it like:
- When a thread needs to wait until another thread terminates: for example when creating a GUI application, we can need to add an action to a button. In this case, if a thread is responsible for building the UI it must end before the thread need to aggregate function to elements on this UI
- When a thread requires exclusive access to a variable: In a case of a counter for example. Otherwise, two threads may overwrite the same variable at the same time
- When a thread requires a condition to continue
When a thread needs to wait until another thread terminates
If we want all the threads to terminate before we continue with our program, we must synchronize them using the join method we discussed earlier. To do so we must add this to our last code
threads = []
# Add threads to thread list
threads.append(thread1)
threads.append(thread2)
threads.append(thread3)
threads.append(thread4)
# Wait for all threads to complete
for t in threads:
t.join()
# Continue here
That is interesting in a case where we want to use the result of the threads for some part of our program.
4. Synchronization II: Locks
When working with threads, we may encounter pretty weird behaviours. And get results that we don’t expect due to a concept called race conditions. Let’s assume there are 20 threads working in parallel on a task (executing the same function). And those threads have to read and update the same variable at a point in time.
At a point in time, 2 threads will access and try to update the shared variable at the same time. The problem occurs when those 2 threads have read the value of the variable before, and then they have 2 local values. If one thread updates the variable, the others will not consider the new value and will overwrite it.
And it may end with a program that gives 85 for example instead of 100. And this is a huge problem. For example, for a banking app, people may end up getting less or more than they are supposed to get.
This may happen for a single line of code too. Because the low-level code of a single instruction may be more than 10 lines. And then the processors may read a few lines and then switch contexts.
For example, this line:
money = money + valwill require 6 lines in low-level instructions. And it may be subject to race conditions.
Let’s take an example to illustrate that:
#!/usr/bin/python
from threading import Thread
import time
money = 0
def updateMoney():
global money
value = money
time.sleep(.001)
money = value + 10
# create threads
threads = []
for i in range(20):
threads.append(Thread(target=updateMoney, args=()))
# start the threads
for i in range(20):
threads[i].start()
# join the threads
for i in range(20):
threads[i].join()
print('The final value of money is ', money)The output is:
- The final value of money is 40
- The final value of money is 30
- The final value of money is 30
- The final value of money is 40
- The final value of money is 40
- The final value of money is 30
- The final value of money is 40
- The final value of money is 50
- The final value of money is 40
- The final value of money is 40
As we can see, our program is unpredictable. And we can solve this problem really easily with python Locks (The same principle exists for other languages)
Python Locks are built to help prevent this kind of behavior. In this case, we must lock the variable, update it, and then release the lock.
To do it must update our code to reflect the integration of Locks
#!/usr/bin/python
from threading import Thread, Lock
import time
money = 0
lock = Lock()
def updateMoney():
global money
lock.acquire()
value = money
time.sleep(.001)
money = value + 10
lock.release()
# the rest of program
And then our result will always be 200
CAUTION
Locks are important, but they may cause other problems. We know now that we may lock a part of our code and another thread will wait for the actual thread to release the lock before accessing the variable. It may occur that two threads lock two different variables and then need the variable that the other holds. It is called DeadLock
- Thread 1 locks variable x and needs variable y, so he is waiting for thread 2 to release the variable y
- Thread 2 locks variable y and needs variable x, so he is waiting for thread 1 to release the variable x
And then they just blocked there, waiting for each other.
An example can be this case:
#!/usr/bin/python
from threading import Thread, Lock
import time
lock1 = Lock()
lock2 = Lock()
def updateMoney1():
lock1.acquire()
print('John block the account of Jane')
time.sleep(1)
lock2.acquire()
print("John send money to Jane")
lock2.release()
lock1.release()
def updateMoney2():
lock2.acquire()
print('Jane block the account of John')
time.sleep(1)
lock1.acquire()
print("Jane send money to John")
lock1.release()
lock2.release()
# create threads
threads = []
threads.append(Thread(target=updateMoney1, args=()))
threads.append(Thread(target=updateMoney2, args=()))
# start the threads
for i in range(2):
threads[i].start()
# join the threads
for i in range(2):
threads[i].join()
The program print :
- John block the account of Jane
- Jane block the account of John
And then freezes. nothing work again
There is no general solution to deadlocks. So it hugely depends on how you write your code. To avoid deadlock try to write a code that avoids blocking 2 threads and a better way to handle this kind of solution is to execute the blocked code one after another. And a good practice is always to wrap the block instructions in a try, catch block. Because if an exception is thrown and your thread stops before releasing a lock it may block the others.
try:
lock.acquire()
assert(False)
except:
print('ouf, we had a catch block')
lock.release()
5. Starting Threads II: Thread Pools and Dependency Graphs
A thread pool is like the name says it, a pool for thread operations. It is mostly used in case we have to create a huge amount of threads (Big data context for example). The global management of those threads can be difficult manually. a huge issue could be in the throughput getting limited too. To solve those problems, we can use a Thread pool. It is mainly used to manage a large number of threads,
- If a thread in a thread pool completes its execution then that thread can be reused.
- If a thread is terminated, another thread will be created to replace that thread.
Let directly see an example of thread pools:
from concurrent.futures import ThreadPoolExecutor
# Large amount of data
numbers = [2,3,4,5,6]
def double(n):
return n * 2
def main():
with ThreadPoolExecutor(max_workers = 3) as executor:
results = executor.map(double, numbers)
for result in results:
print(result)
main()This program will print the inspected result, but it is not sequentially executed. We have specified 3 max threads to work on the task. It can be very helpful in cases like the previous one when we need some threads to be executed on a large amount of data and we get the result.
To use it, we must first manually split the data to be computed by each thread before passing it as a parameter to the thread pool.
On the other hand, dependency graphs are computations composed of several atomic parts/tasks. And some tasks require the result of others as input.
Let’s imagine a scenario, where we have different data sources and on each data source we must apply a clean function that is not common to every data source: It may end ups with dependencies graphs like this one:
f1 -> f2,f3,f4,f5
f2 -> f3, f5
f3->f5
f4->_
f5->_
To use thread in this context, we must use dependency graphs.
There is no standard way to deal with this, but the most common solution is to use asynchronous programming. And in this case, we can make a promise, that the dependent function will wait until they get the result from their parent, and then continue the computation with the result they get. The python asyncio package is a great solution to work asynchronously in python.
6. Open MP
After hard work, we can introduce a master standard that is built to completely facilitate the integration of threading in your code. It has many implementations in different languages. Actually in python due to the restrictions on threads with GIL, there is no standard way of dealing with it. you may need to check out the java version of OpenMP or some libraries like cython, Pythran, …
7. Conclusion
Despite the fact python has many restrictions with Threads, it is always possible to parallelize our code using the thread approach. It is helpful in a data analytics environment setup to use the full computational capacities of our devices… But most of the time, the computation is just too high and the amount of data is too big to be handled by a single computer. In this case, we must use a network-based environment and connect multiple computers, using the computation power of each. This introduces some concepts like MPI that we will discuss in the upcoming chapters