Distributed file systems: Everything you need to know about it

Module name: Distributed Storage (DFS – Distributed file systems, Database)
The last module start here: https://ulife.ai/stories/everything-you-need-to-know-about-threading-with-python
Big is not just about computation. If we want to compute a huge amount of data, we need to find a way to store them so they can be easily accessible. And for that reason, we have many solutions like File systems and databases spread across computers. In this section, we will talk about distributed file systems like (HDFS, GFS, …), and Database partitioning and why you may need a NoSQL database for storing big data.
Introduction
In this section, we will discuss how to store petabytes of data in multiple computers and make them always available and coherent. We will introduce Hadoop Distributed File Systems, Google File system (that power google drive), …
1 – Why do we need a DFS
At the beginning of this book we have introduces the concept of big data and how huge the data we may want to store are. Let’s consider for example petabytes of data. Can we keep all that on a single machine? (Of course not). So we need a solution to store files on many computers.
There comes DFS. It can help to store extremely huge amounts of data in many computers in a way that you can access it at any time, without inconsistency, in an abstract way for the users so they don’t have to mind what is going on in the background, they just access the files as they will do in their local computer.
This then creates many challenges that we will address in the upcoming sections. We can cite for example:
- The Read problem: If you store a file on many computers how do you read that file? This leads to a scalability problem also as we may need to perform multiple reads and writes on large data. We need to do that as fast as possible
- How do you update the file? Do you add content anywhere on any computer?
- What happens if one computer dies? Will we lose everything? (fault tolerance problem)
- How do we hide the complexity of such a system from the end user? For example, when you go to google drive you want to be able to create, delete, and edit files and folders like on your local machine ignoring the fact that it is stored on a distributed system. (transparency problem)
- Performance and availability problem: How to make sure all the requests to the DFS are executed fast and the system is always available as a normal disk could be.
2 – How does a DFS work?
In the DFS, files are split and saved in many servers and managed in a way that solved most of the challenges we had stated previously. And for that, we need a specific configuration. We must define some concepts first:
- Node: It is a server in our set of servers. It can be the one storing data, or metadata about our files.
- Chunk: It is a part of a file. When you split the file into multiple parts, you get chunks of that file.
- Chunk Nodes: Those servers store all our files in chunks. So one file can be stored in many chunk servers. One or many chunks by nodes.
- Master node: He is like the chief here. Because he is the one storing metadata about the files and the nodes. It can for example contains where a part of a file is stored on which chunk node. So if we have for example this gigantesque file we will split and save it on different nodes. The master node will keep track of which chunk of this file is saved in which chunk node [Some images]. Which chunk id refers to which chunk node, and where are those chunk nodes located?
He is also responsible for the security access control of the different files.
- Clients: It is the interface with the user. For example your google drive interface. It makes much of his interactions with the master node to know for example where a specific chunk is located or to get that specific chunk.
- Replication/replica: It is the mechanism of copying data on different locations to ensure that if there is a problem with one location we still have a backup version of the data in other locations.
Local computer tree vs online servers trees.
In your local machine, your file is saved in some part of your local disk, and then you can just access it easily by specifying the location. (see example tree)
But when it comes to a DFS, when you ask for a file located at /home/user/some_file, for example, the process is way more complicated. And completely depends on the action you are trying to archive. We first have to point out some architectural basics:
- The failure problem: What happens when a server loses a chunk of the file, we will not be able to reconstruct the complete file we had previously. For that reason, there is a duplication mechanism implemented in DFS that helps to overcome such problems. When you save a chunk on a server, the same chunk is saved in many other servers (called replicas). The initial server containing the chunk is tagged as the primary replica. So when one server has a problem, we will not lose the complete files we had saved previously.
- The fault tolerance problem and how to detect that: What happens when a server trash: The master nodes keeping track of the different files has a table tracking all chunks and also the chunk server locations and their state(alive or not). The master node can have all those metadata because he pings the chunk nodes and they send a signal to say “Hey I am alive” (heartbeat by default every 3s). And when he does not receive that message for a long period(by default 10 mins), he considers the server is down, he deletes the server from his table, and all the chunks located on that server are replicated into other servers so we have the same number of replicas for each chunk and his table is updated.
Writing
The main problem with DFS is how your file is written on a distributed environment on many servers. Surprisingly the process is simple. When you have a large file, you split it into parts
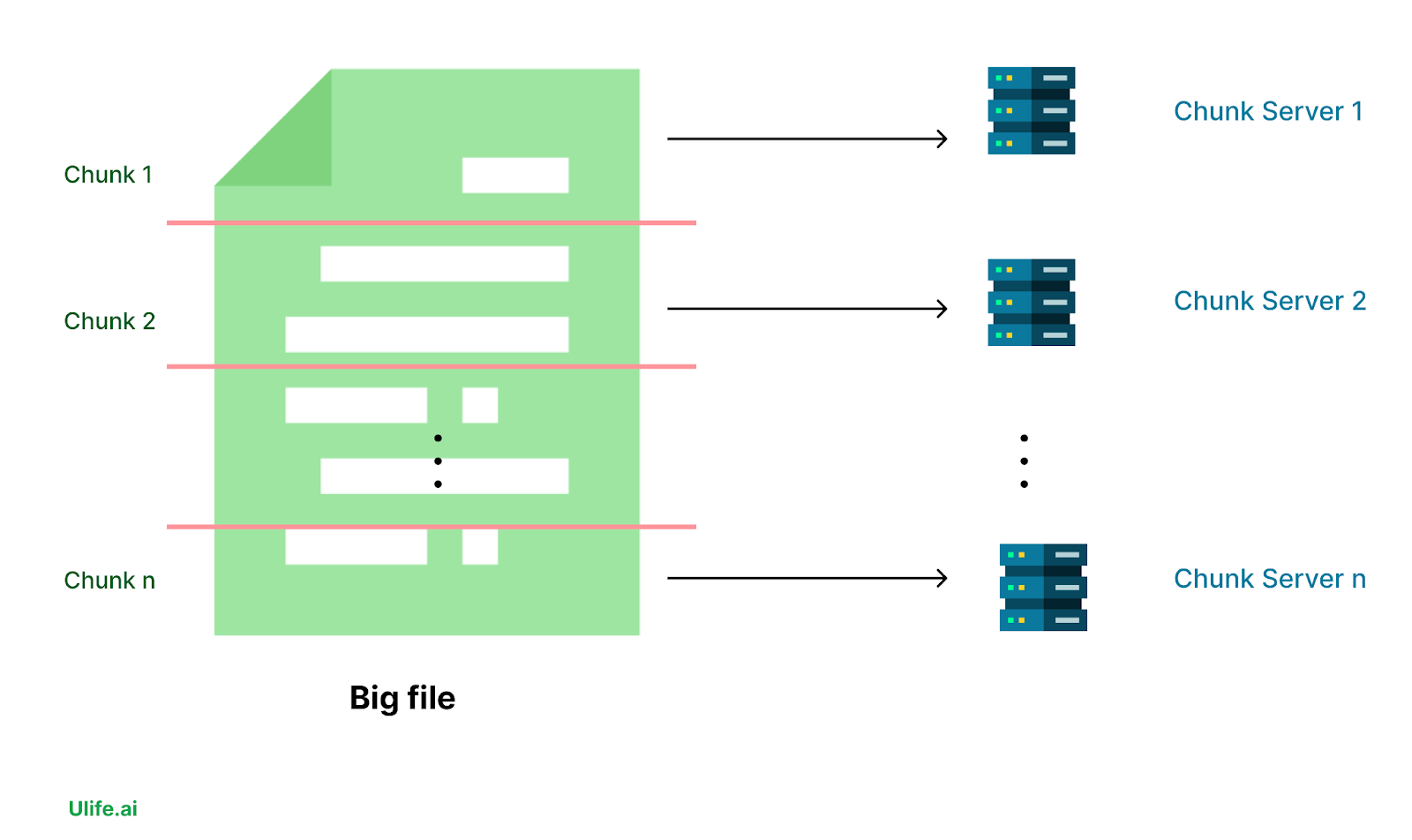
And each chunk is saved on a chunk server. We have the master server defined previously which is supposed to know where each chunk is located so we can easily access them.
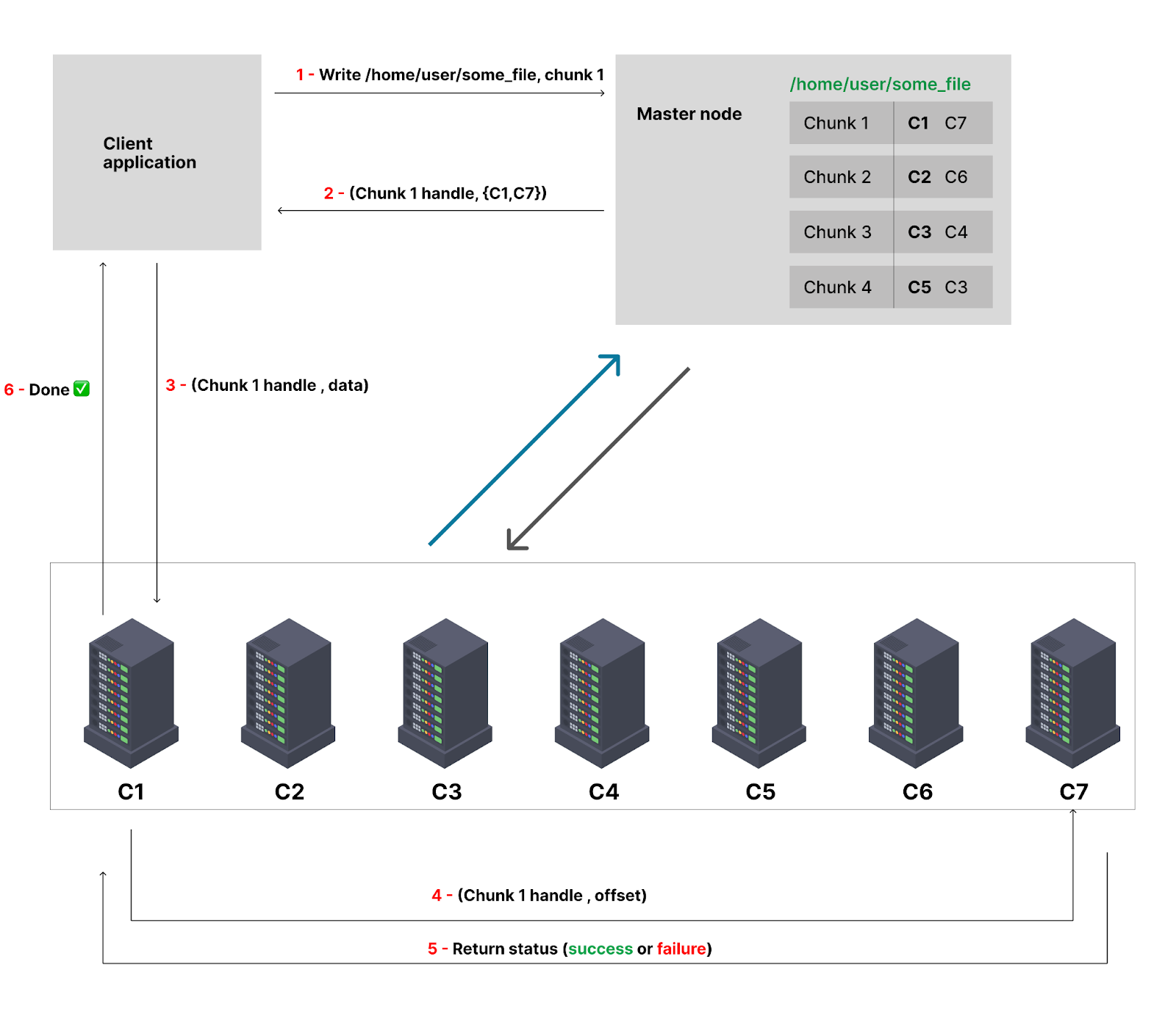
The client can now contact the primary replica and send him the information about the file to save. The main replica saves the chunk. In the background, he synchronised with the other servers to save a copy of the file on them. So an internal copy is done between chunk nodes and after the operation is completed, they contacted the master node to notify him and the master node can save that metadata. In the end, if everything was done and the chunk has been successfully saved on all the chunk servers, the client receives a done message from the primary replica. [See image]
NB: Writing operations can be efficient if the chunk is added at the end or challenging if we write in the middle
Reading
The process for reading a file in a Distributed environment is organised like this.
The client will ask the master node for information about the path you are trying to access.
The master answer back with the servers where are located the file and the client can then read the content he is trying to read. The process is straightforward.
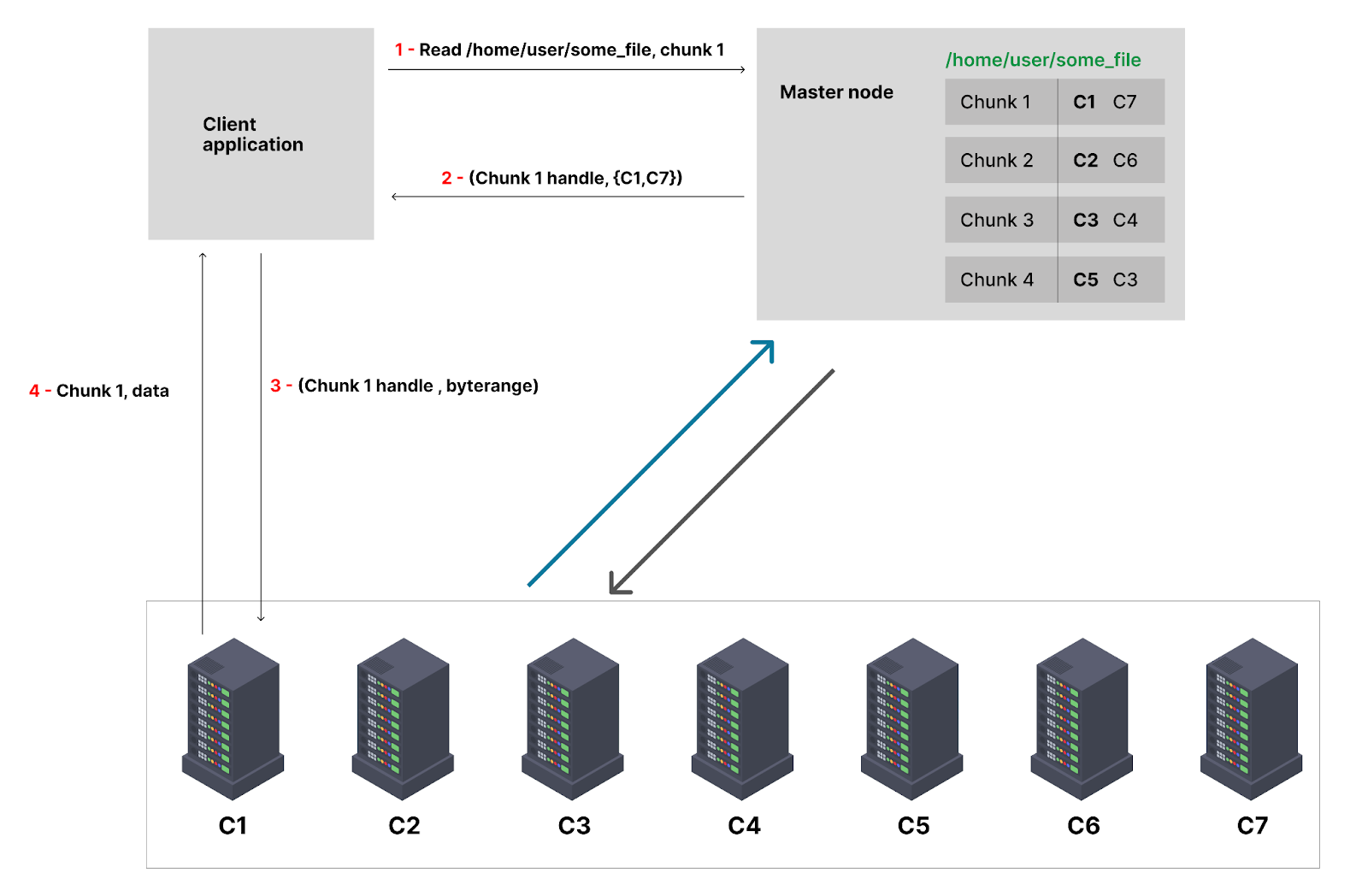
Recap about Replication Management
- Distributed file systems are often hosted on large clusters: Many nodes mean the risk that one of them fails increases
- Each chunk is stored redundantly on several chunk nodes (Replication) and we have described this mechanism earlier. By default, each chunk has 3 replica
- Chunks need regularly send an “ I am alive message” to the master node (heartbeat) described earlier as well. By default, this signal is sent every 3s
- A chunk without a heartbeat for a longer period is considered to be offline or dead. By default after 10 minutes
- If a chunk node is found to be offline, the name nodes created new replicates of its chunks spread over other chunk nodes. (Until every chunk is replicated 3 times again)
Source: Big data analytics, Uni-Hildesheim
Examples of DFS
- Windows Distributed file systems
- GFS(Google)
- Lustre(Cluster FS)
- HDFS (Apache)
- GluterFS and Ceph(Redhat)
- MapR FS
Let’s see the architecture of 2 DFS: GFS (Google file system) and HDFS(Hadoop distributed file storage)
GFS
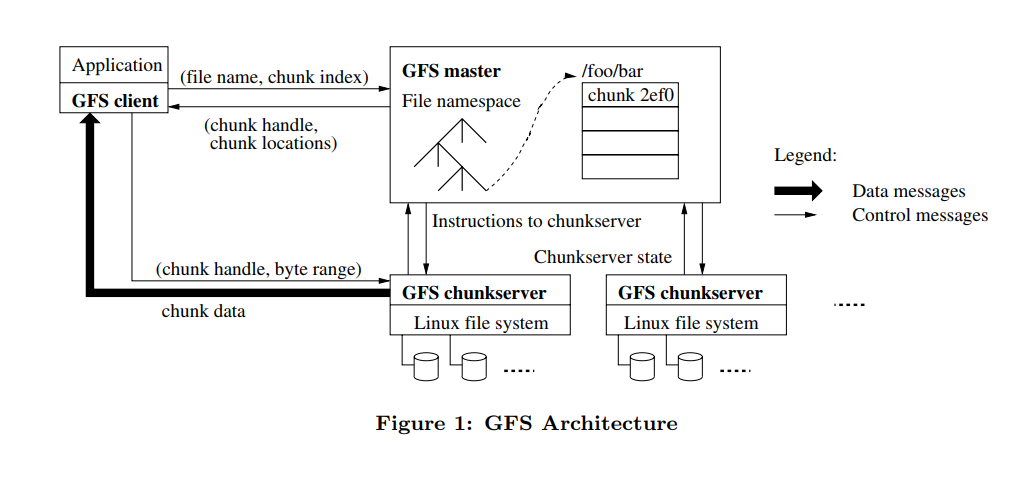
HDFS
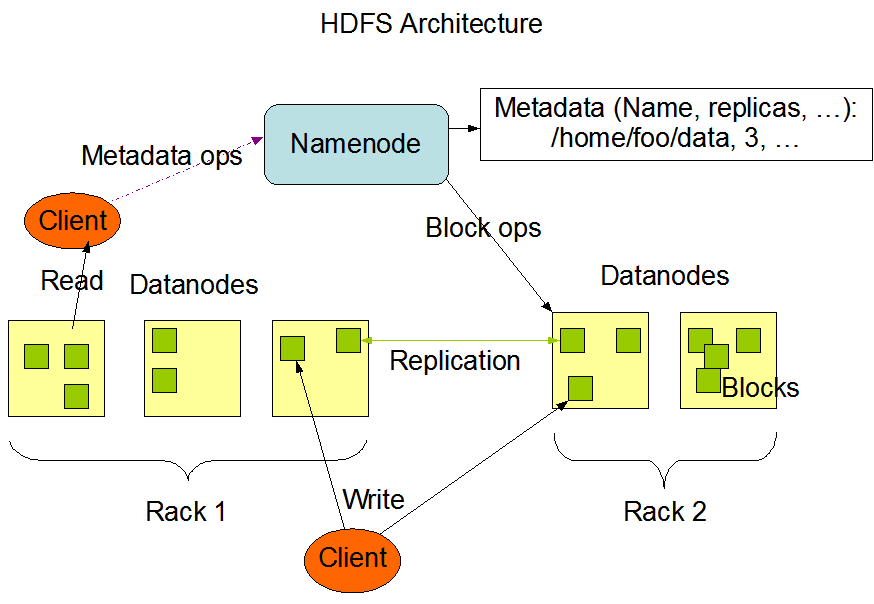
| HDFS | GFS | |
| Chunk size | 128Mb | 64Mb |
| Default replicates | 2 Files | 3 Chunks nodes |
| Master | NameNode | GFS Master |
| Chunk Nodes | DataNode | Chunk Server |