January 15, 2023
NoSQL for big data: introduction and Scalability
January 15, 2023
NoSQL for big data: introduction and Scalability

January 15, 2023
After the success of relational databases, most companies had their data carefully saved in SQL databases in a structured manner with all the advantages that come with it. But there was a problem that those companies faced, the need to constantly change the architecture of the data they have saved, maybe to archives or for their applications. That operation is extremely costly for relational databases. There was a need to create a database that could easily change and could be scaled easily to contain a huge amount of unstructured data. If we come back to the introduction section, you may have noticed that big data are often raw data collected from multiple sources with different structures and formats. Therefore there is a need for storage technology that could save that type of data. Another particularity tight to big data is they must be easily saved in a distributed environment, which means the cost of adding new nodes needs to be cheap. But unfortunately, SQL databases can only support structured data and scaling/adding nodes is an expensive operation as it may affect existing data structures.
For all those reasons, a new type of database has been created: NoSQL databases. People are always confused by the name NoSQL as it could mean No SQL, but it means Not Only SQL, and they have been created for storing and making the retrieval of data more flexible compared to SQL databases.
The main advantage here is the simplicity of design, which means it is extremely simple to design and update the structure of the data saved in those databases. The format of your data could be changed at any time with no problem. And they are also easy to scale, meaning adding new nodes is extremely simple, mainly because of their design.
We also have to note that due to its design, NoSQL databases are faster in some operations but could also be less performant than RDBMS(Relational Database Management Systems).
People may be more familiar with Document Databases like MongoDB, but there are many NoSQL databases. The following are the different types of NoSQL databases with some implementations:
I also need to introduce data lakes and data warehouses. As you may see in the following image, data loaded in data lakes and data warehouses come from different sources and could have a highly variant structure. They are really important data sources for big data analytics and thus need a proper database for saving unstructured or highly variant data. NoSQL is often the best solution for that need, where companies could save large amounts of data from different sources without having to deal with consistency.

We must first introduce what a key-value store is before presenting most of the NoSQL databases. If you are familiar with JSON, you already know Key-Value Stores. They use Assiosicative arrays or Map data structures as fundamental data models. NoSQL databases often present the data as a collection of key-value pairs. The format is the following:
{
“key”: “value”
}
An example could be an employee instance:
{
"name":"Marc",
"position": "Big Data engineer",
"salary": "100.000",
"age": 33
}Many NoSQL databases use that structure to save big data. And thus, saving the employee with or without the age field is not a problem. The data could still be processed.
One of the most popular NoSQL database types is Document Databases with their star MongoDB which is OpenSource, by the way. Their main characteristics are that traditional tables in relational databases are represented as collections, and rows are Documents. And those documents are just key-value stores that could be possibly nested. This means we could have a document like this:
{
"_id": ObjectId(_5455r45ds54e8awr8r78t787t)
"name":"Marc",
"position": "Big Data engineer",
"salary": "100.000",
"age": 33,
"insurance":{
"name": "Insu Co.",
"location": "Paris"
}
}
with insurance being a document. They are also schemaless, which means there is no fixed structure to the data you save. As mentioned earlier, one employee could have an insurance document embedded and another not.
You may have also noticed there is an _id key in each document. Documents are identified by an ID of type ObjectId, generally stored in a field called _id. They are a unique key identifying the document.
A collection is a set of documents. As simple as that. The concept of tables in relational databases is represented in Document databases as Collections.
You may be wondering, in SQL databases, we have relations to link different entities. How do we do the same with relational databases?
So we have two ways of doing that, and each with its advantages and drawbacks.
# employe
{
"_id": ObjectId(_5455r45ds54e8awr8r78t787t)
"name":"Marc",
"position": "Big Data engineer",
"salary": "100.000",
"age": 33,
"insurance": ObjectId(_kjjd6d585d565d85d25)
}
# Insurance
{
"_id": "_kjjd6d585d565d85d25"
"name": "Insu Co.",
"location": "Paris"
}
And this will make it possible to reference it in many other documents and make the update easier also. But the reading will be less fast than with embedded documents.
We may give a concrete example of the installation and usage of a NoSQL database (MongoDB, for instance), but it will make the document longer. We will add some resources so you can learn that aside.
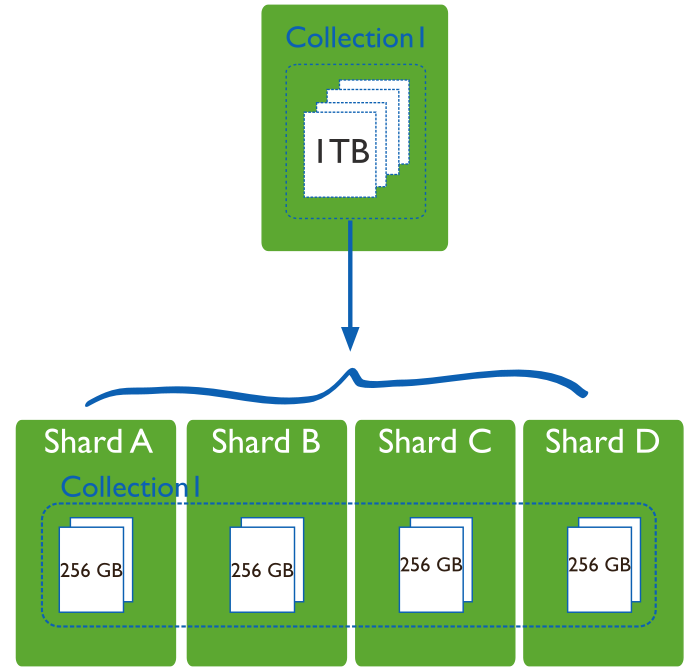
This is the most important aspect of NoSQL databases for big data applications. You may know about horizontal scaling. It means adding additional nodes or computers to scale an application or database.
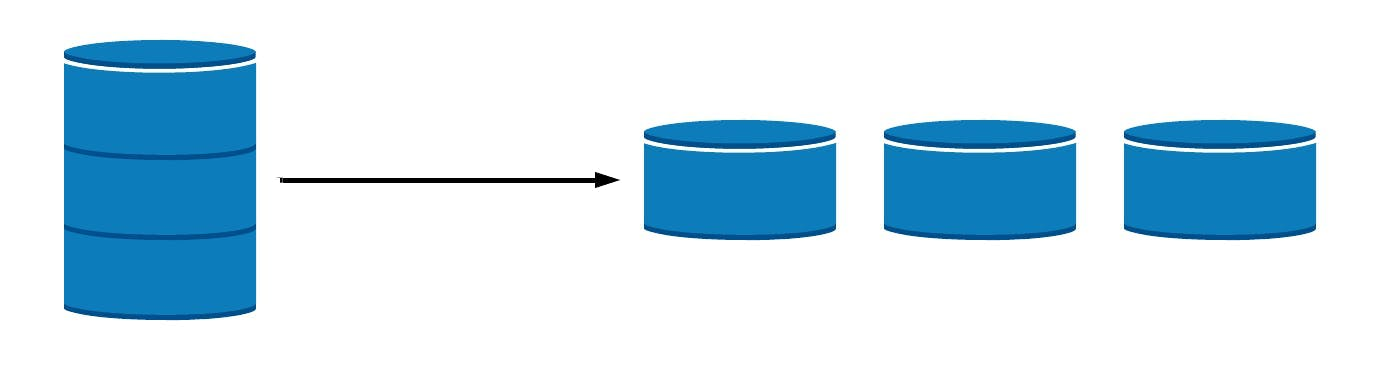
It is hugely important for big data as it can permit infinite scaling by adding more and more nodes as the data grows. It is extremely easy to do with NoSQL databases like MongoDB. Adding nodes can be as easy as typing a few commands. And the database will consider the newly added node automatically in its configuration.
In this process, we obviously have to set up those nodes in a way that one of the nodes could be easily called by the App server, depending on the mechanism you choose to distribute your data.
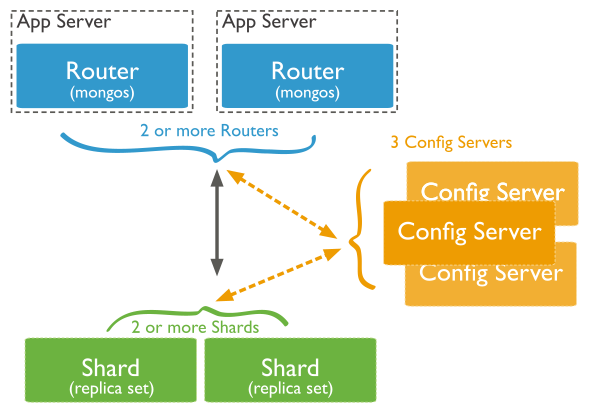
Caution: as we are talking about big data here, it is always better to use corresponding technologies to work on distributed data. Querying a Router Node directly could be extremely slow and thus is not highly recommended for common usage. It is better to use technologies like map-reduce, which we will introduce in the following chapters, to work on sharded big data.
Key-Value database: Databases like Redis makes it easier to save and retrieve key values pair. there are often used as a faster alternative to direct access to databases. it may help to save information like sessions and user information for quick access and is also used in microservices architecture to share data between services.
Graph databases: Those databases save data in a human-like way by creating highly connected data. They are developed to be faster with joint operations. The most popular tool for that need is Neo4J, which has an entirely different query language for saving and accessing data. It is interesting for application which needs graph-like queries: Shortest path queries, Pattern Queries, …
Column: The most popular implementation here is Cassandra DB. It is designed for big data and can handle highly distributed data with no single point of failure.
With the nature of information saved in a big data context, NoSql databases are prominent for the use case. Documents, Column and many types of NoSQL databases are the go-to solutions for big data application because of their capacity to handle highly distributed data and to provide an environment where distributed computing on those data are easier and more flexible for developers.